
[알고리즘] 최대점수 구하기(냅색 알고리즘)
(문제) 최대점수 구하기(냅색 알고리즘)
이번 정보올림피아드대회에서 좋은 성적을 내기 위하여 현수는 선생님이 주신 N개의 문제를 풀려고 합니다.
각 문제는 그것을 풀었을 때 얻는 점수와 푸는데 걸리는 시간이 주어지게 됩니다.
제한시간 M안에 N개의 문제 중 최대점수를 얻을 수 있도록 해야 합니다.
(해당문제는 해당시간이 걸리면 푸는 걸로 간주한다, 한 유형당 한개만 풀 수 있습니다.)
입력설명
첫 번째 줄에 문제의 개수N(1<=N<=100)과 제한 시간 M(10<=M<=1000)이 주어집니다.
두 번째 줄부터 N줄에 걸쳐 문제를 풀었을 때의 점수와 푸는데 걸리는 시간이 주어집니다.
출력설명
첫 번째 줄에 제한 시간안에 얻을 수 있는 최대 점수를 출력합니다.
테스트케이스
| 입력예제 | 출력예제 |
|---|---|
| 5 20 10 5 25 12 15 8 6 3 7 4 |
41 |
| 9 50 12 7 16 8 20 10 30 15 10 5 25 12 15 8 6 3 7 4 |
101 |
| 12 70 5 2 11 5 12 7 16 8 20 10 30 15 10 5 25 12 15 8 6 3 7 4 3 2 |
141 |
해결방법
최대로 중복 이용해서 값을 구할 경우 –> 정 . 방 . 향 (최고 방법)
최대로 중복 없이 이용해서 값을 구할 경우 –> 반 . 대 . 방 . 향 (최고 방법)
최대로 중복 없이 이용해서 값을 구할 경우 –> 정 . 방 . 향 . 2 . 차 . 원 . 배 . 열
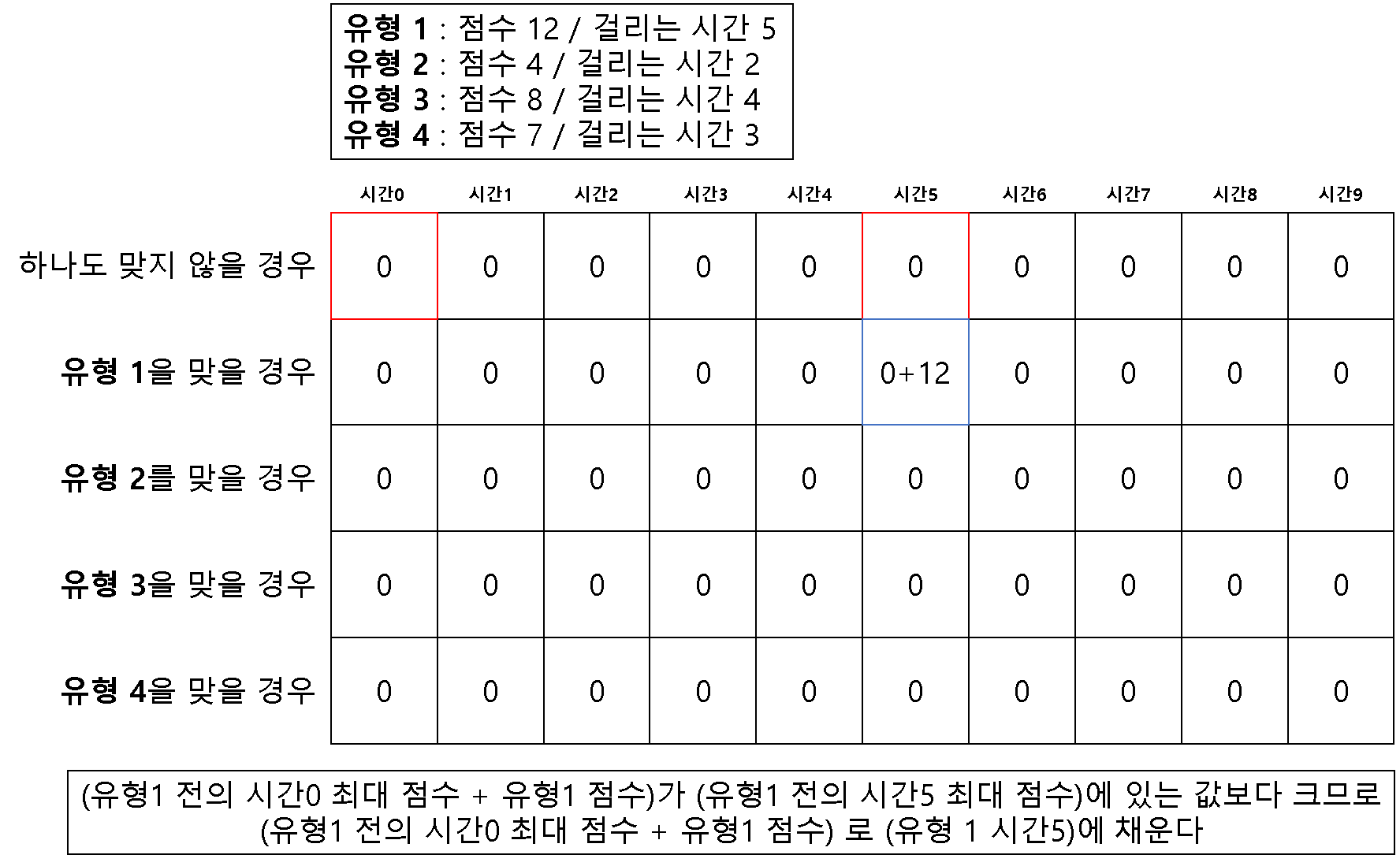
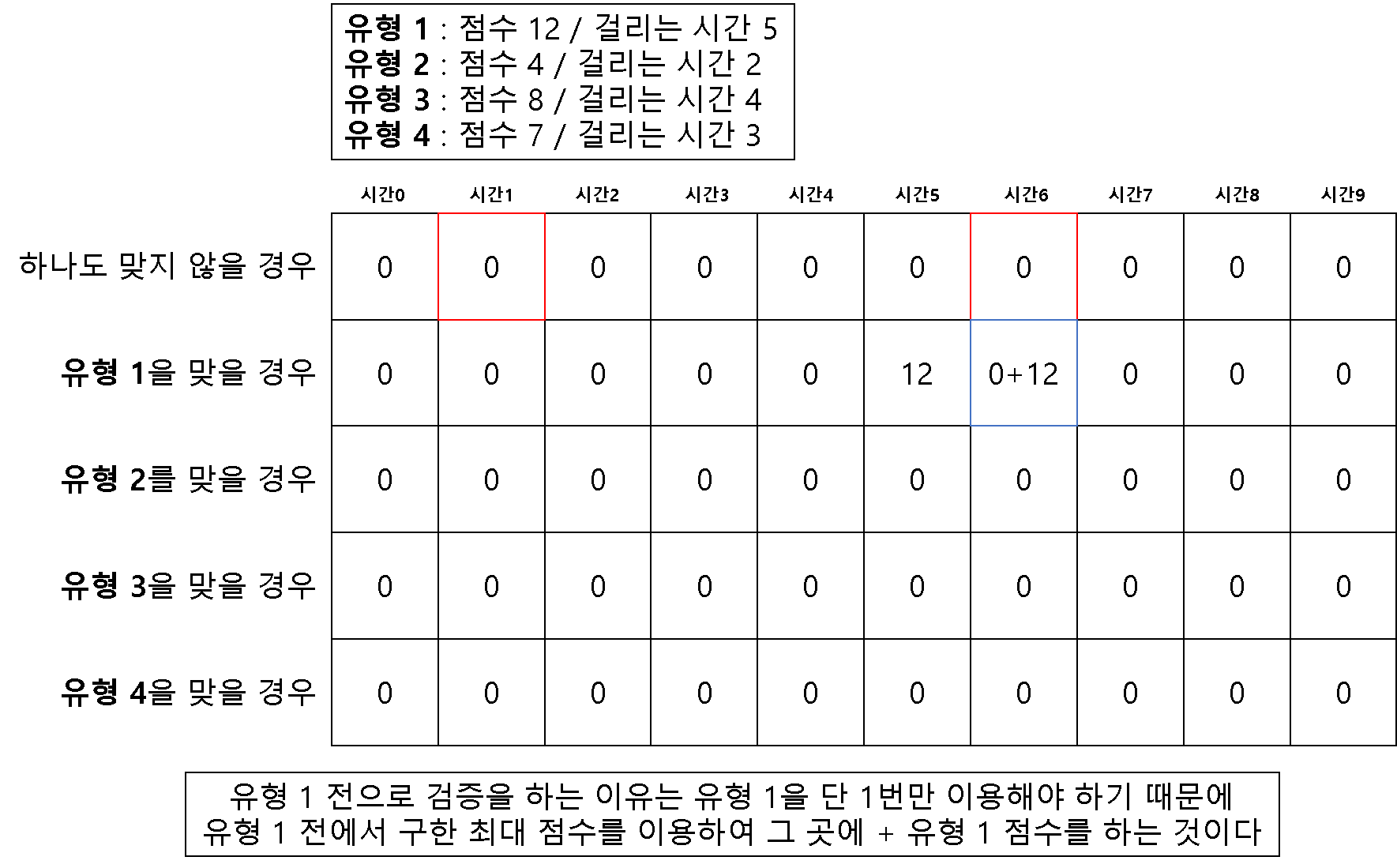
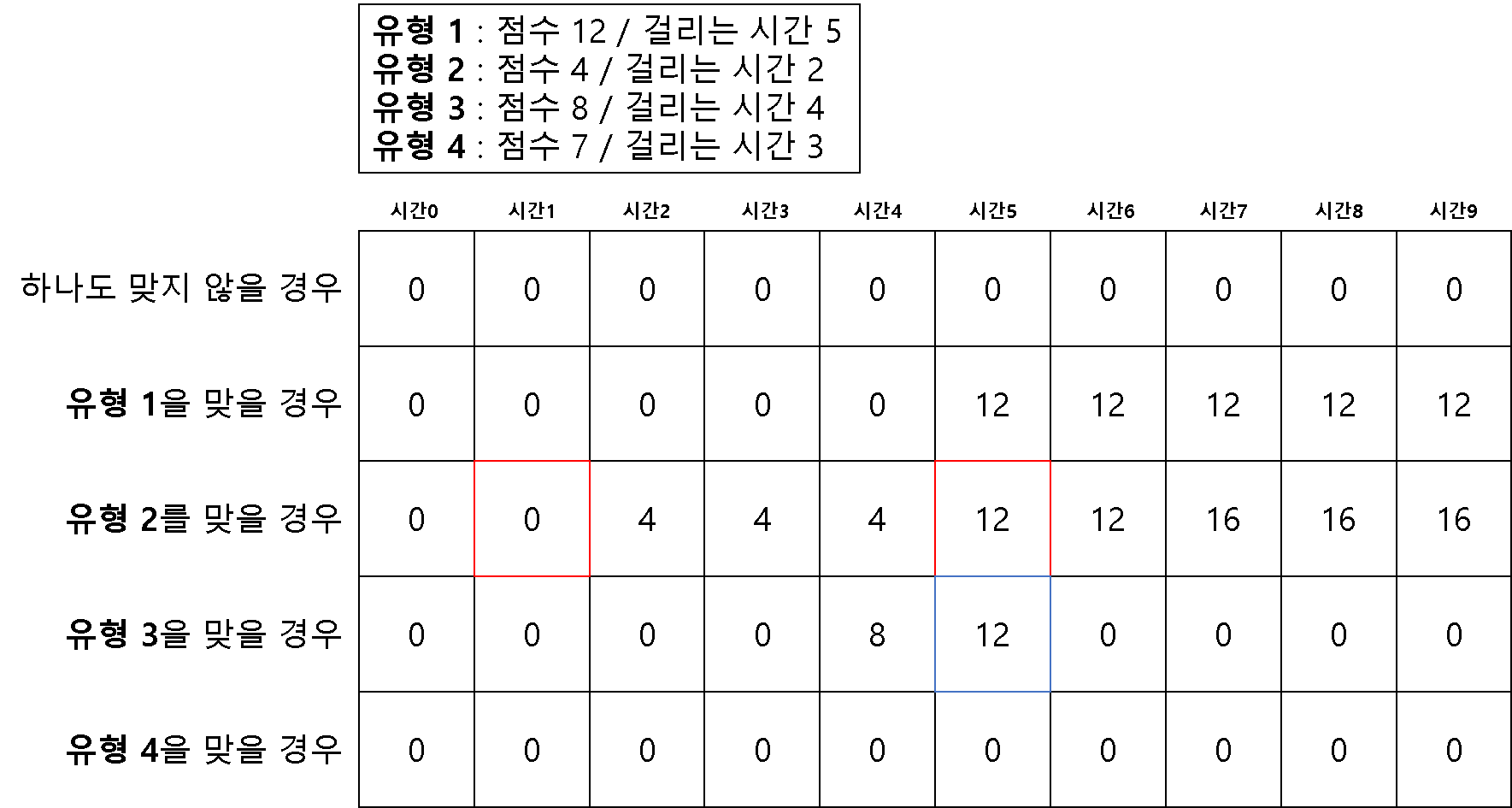
방법 1 ) 2차원 배열을 이용한 다이나믹 테이블

















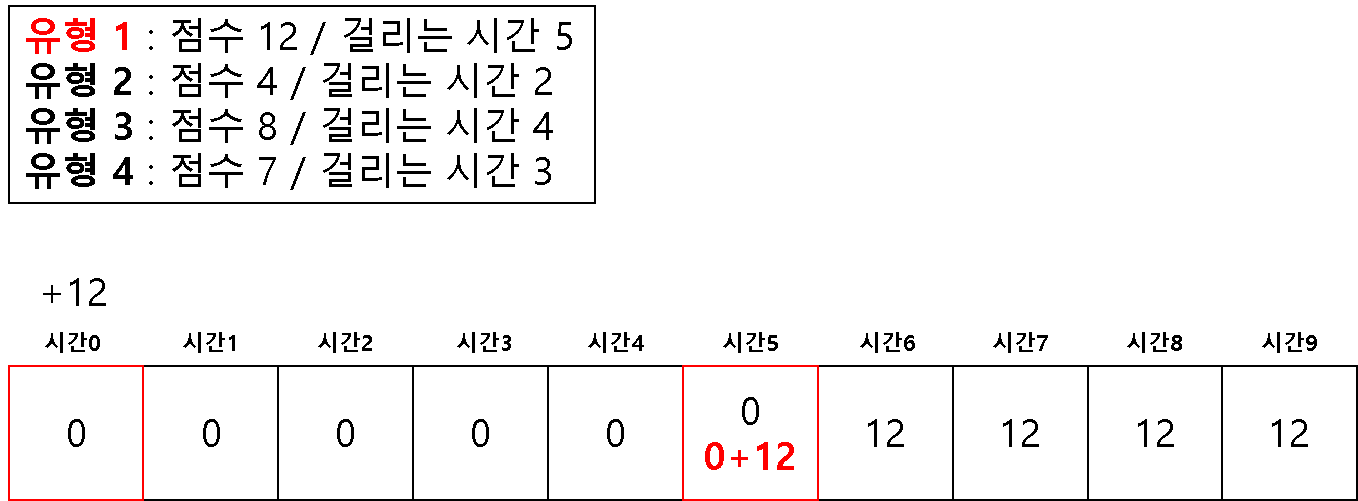
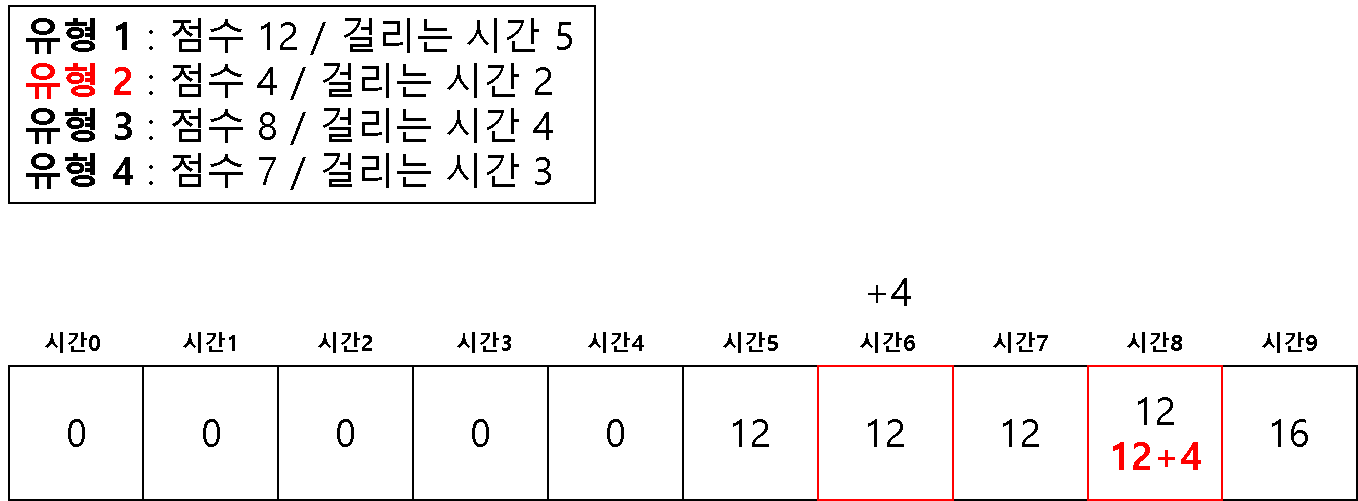
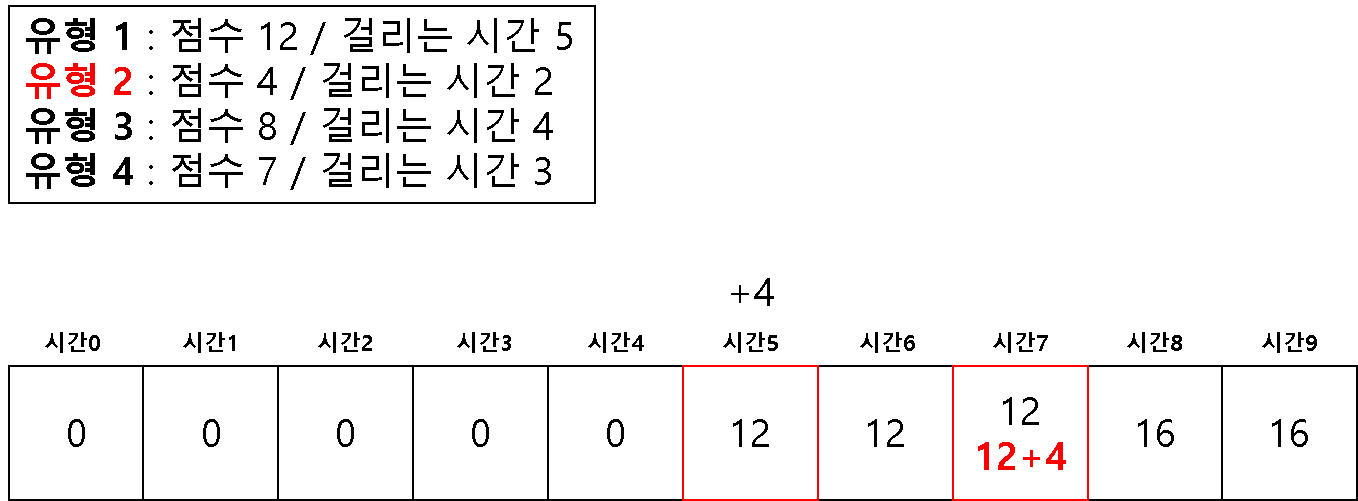
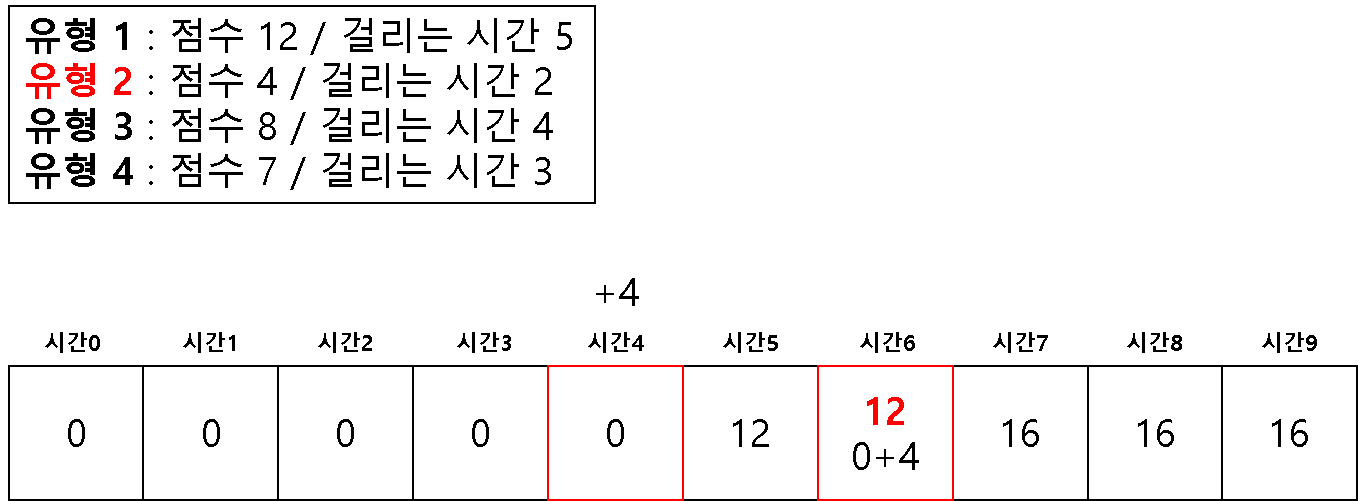
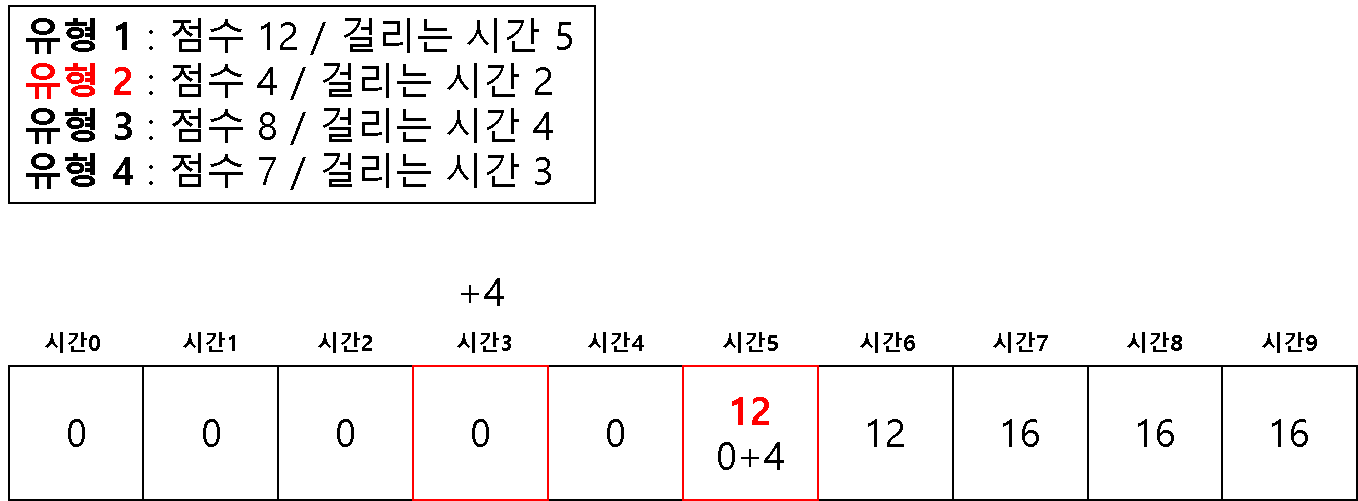
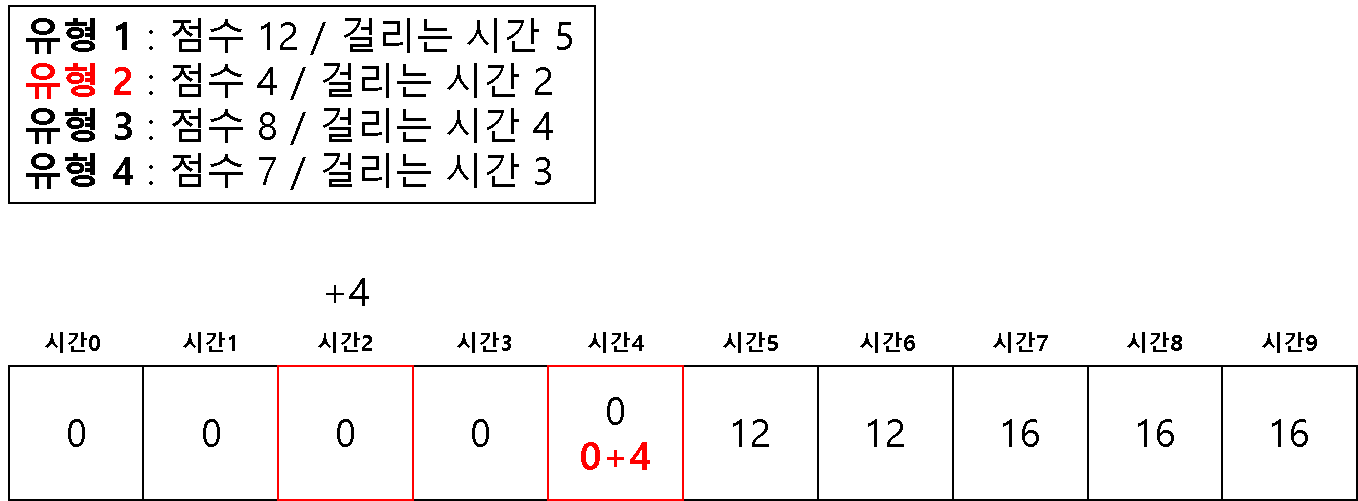
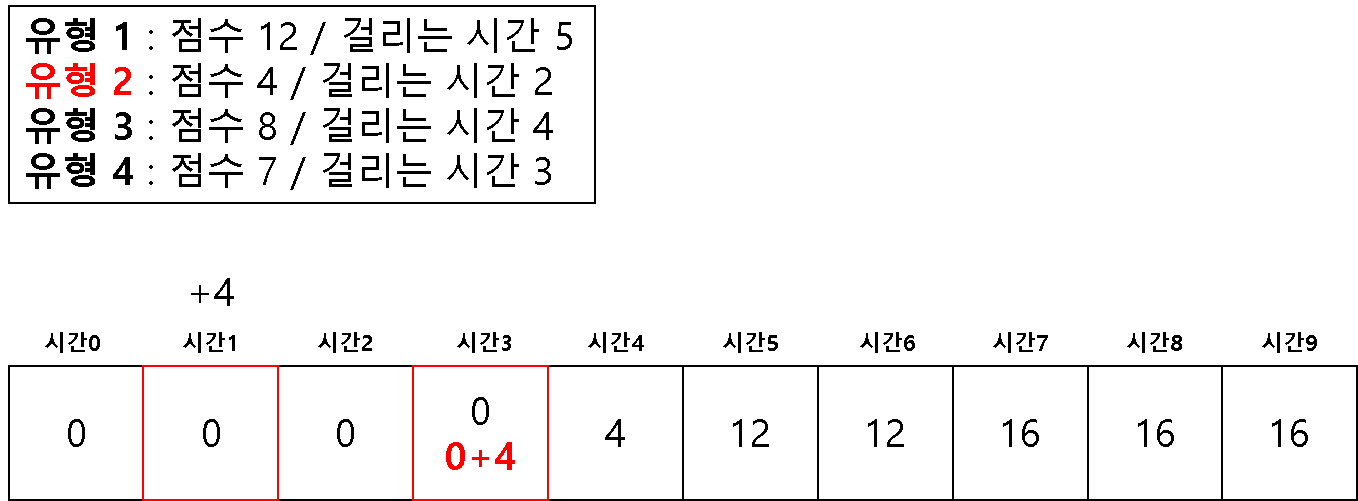
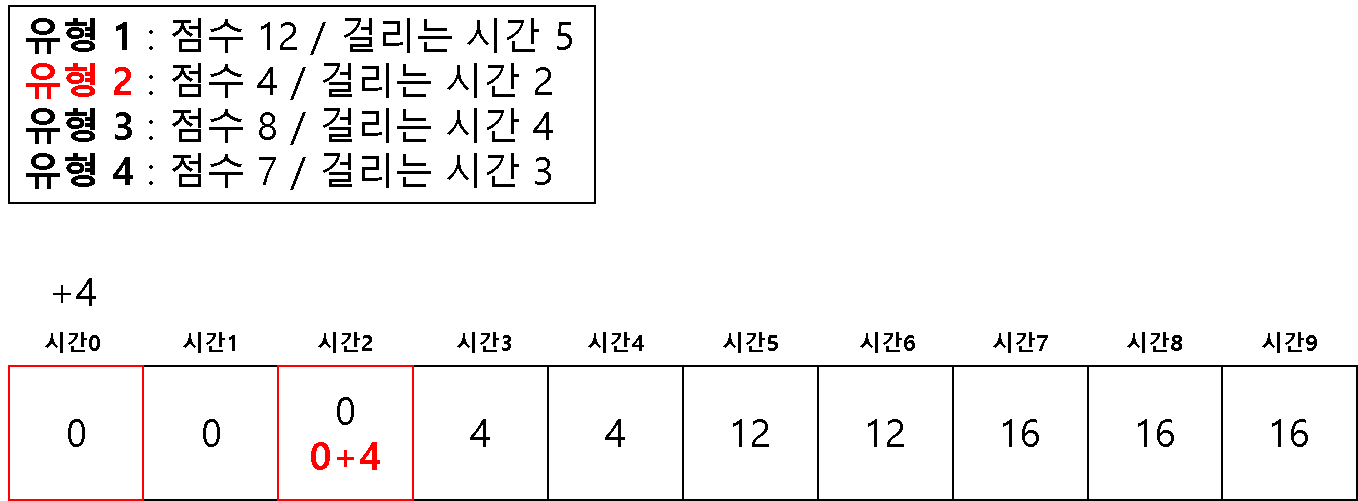
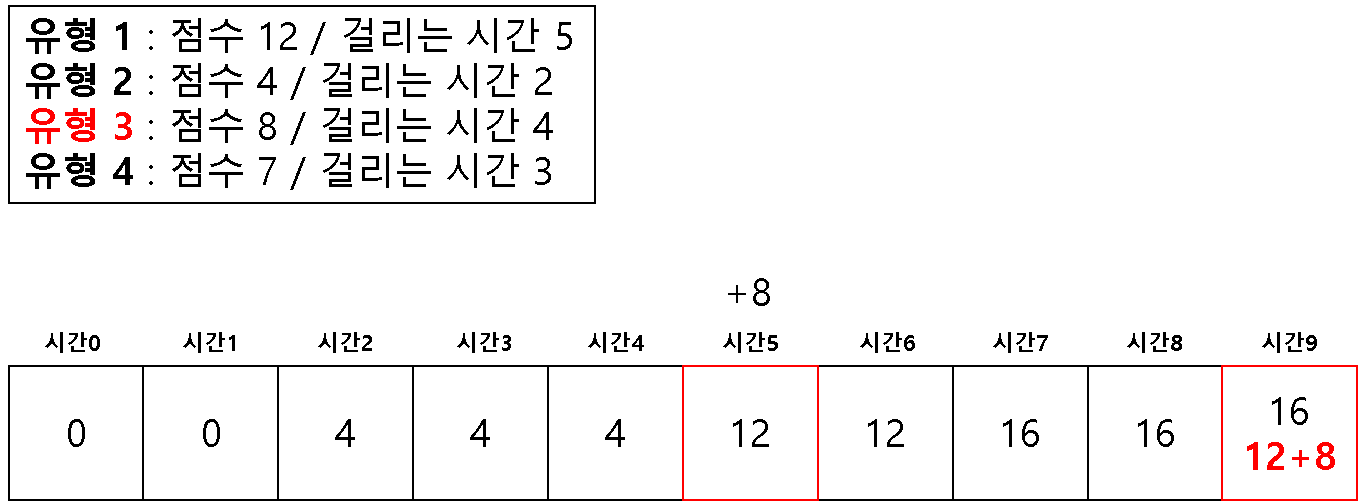
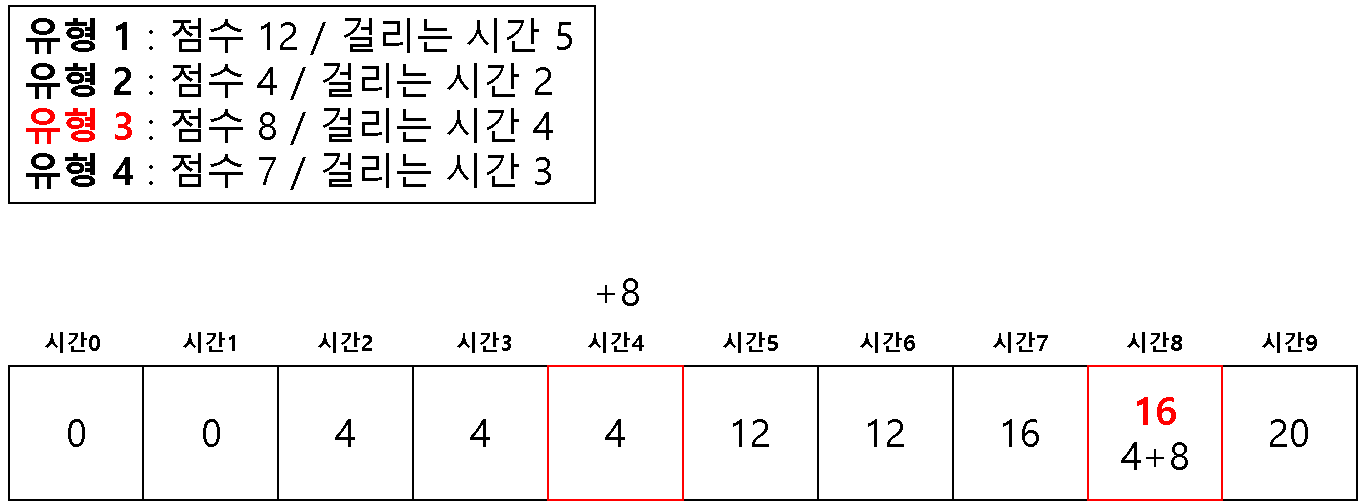
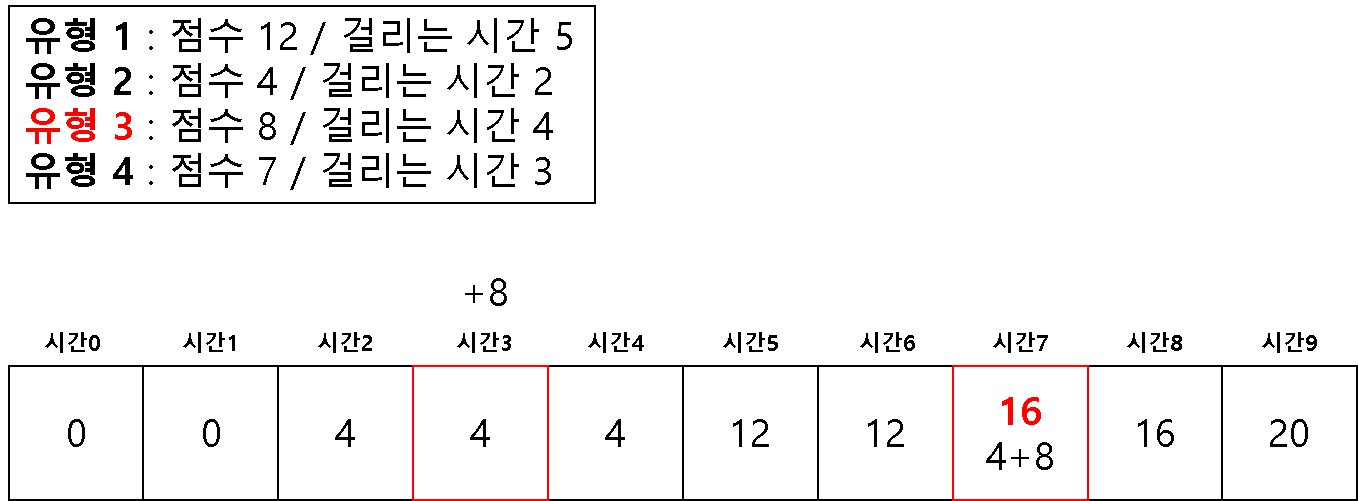
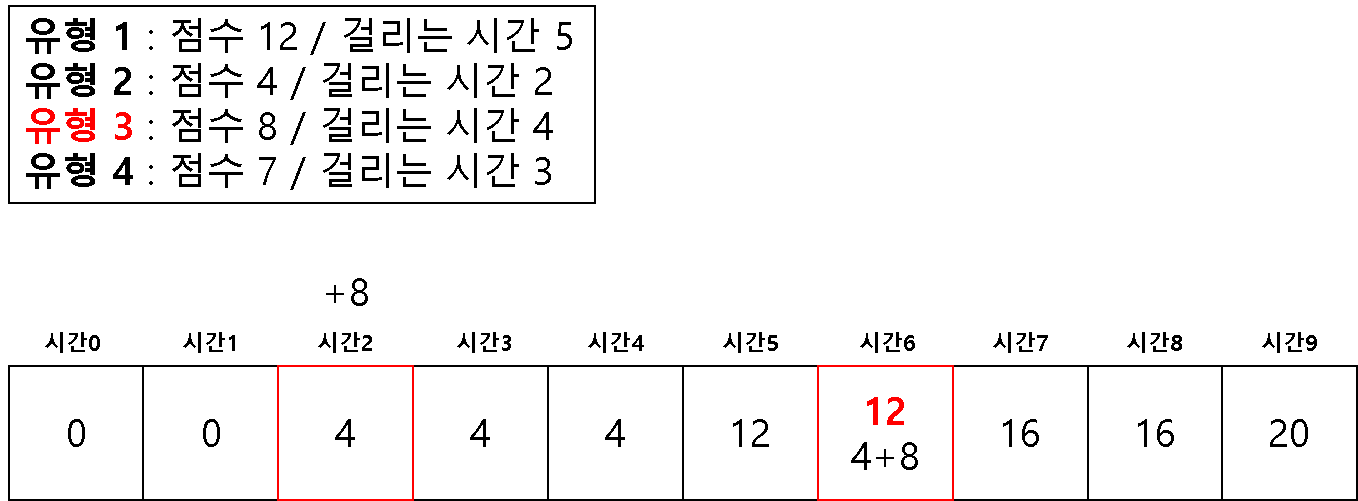
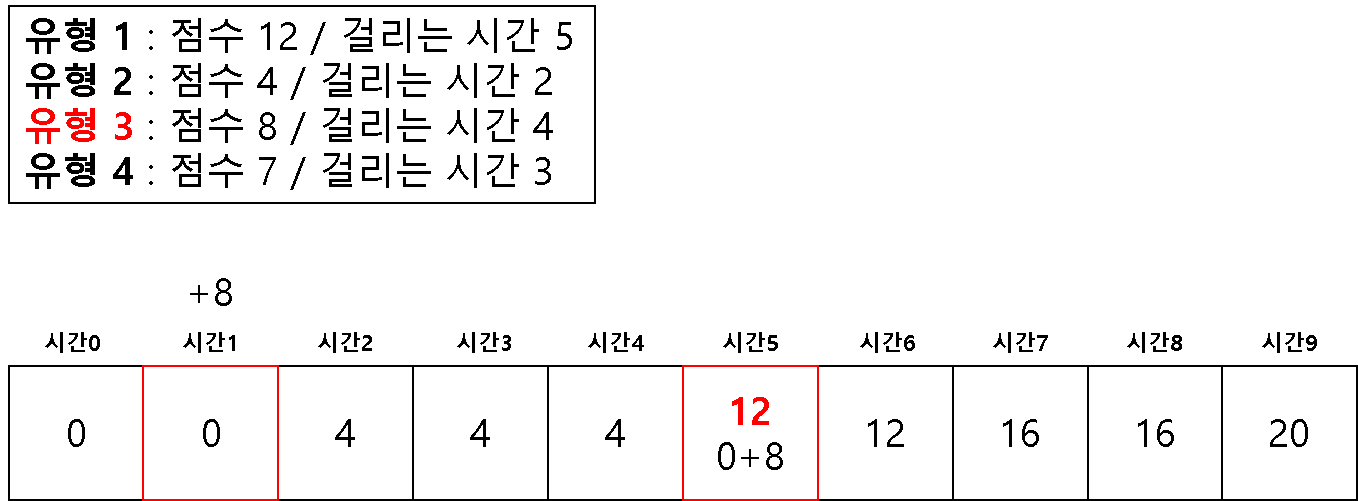
방법 2 ) 1차원 배열을 이용한 다이나믹 테이블






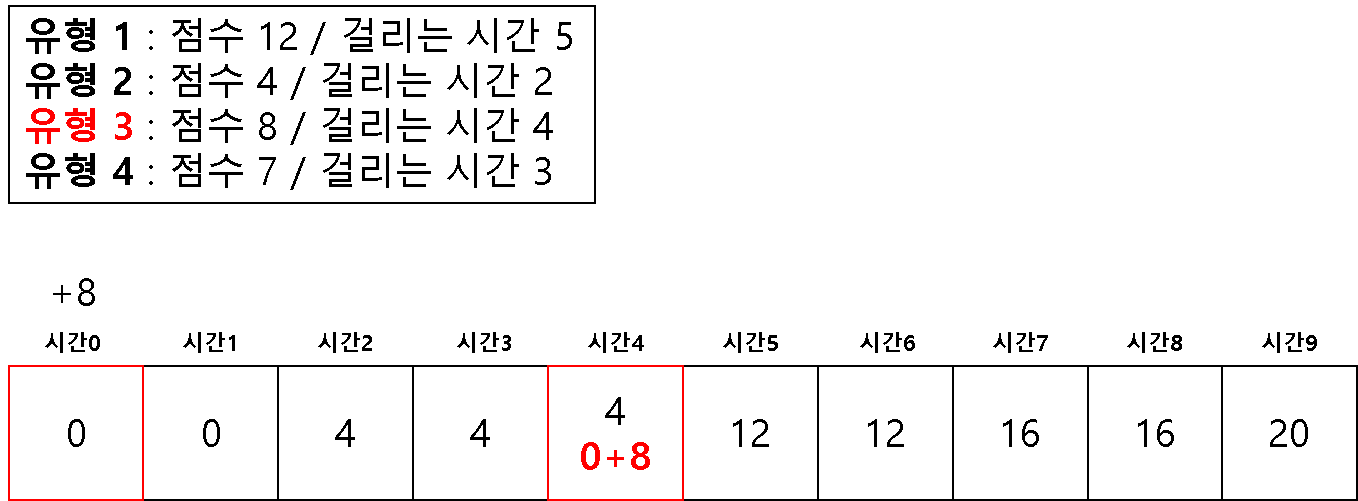
코드
2차원 배열 방식
n, m = map(int, input().split())
# 문제[?][0] : 점수
# 문제[?][1] : 걸리는 시간
questions = [list(map(int, input().split())) for _ in range(n)]
# X분 안에 걸리는 시간의 최대 점수가 각 X 인덱스 안에 들어간다.
dt = [[0] * (m + 1) for _ in range(n + 1)]
# 한 유형당 한개만 풀 수 있다 (중복 불가능)
# 2 차원 테이블에서 생각
# 행은 유형의 종류
# 열은 들어갈 수 있는 최대 점수의 경우
for idx, question in enumerate(questions):
for j in range(question[1], m + 1):
# 전의 유형에서 걸리는 시간의 최대 점수 값을 넣은 인덱스 비교하여
# 값이 큰 것을 현재 유형의 걸리는 시간 인덱스에 할당
dt[idx+1][j] = max(dt[idx][j], dt[idx][j-question[1]] + question[0])
print(dt[-1][-1])
1차원 배열 방식
# 2 차원을 이용해서 하면 시간 복잡도 문제가 생길 수 있다고 한다.
# 1 차원으로 하는 경우 (반대로 값을 채우기 시작한다!)
n, m = map(int, input().split())
# 문제[?][0] : 점수
# 문제[?][1] : 걸리는 시간
questions = [list(map(int, input().split())) for _ in range(n)]
# X분 안에 걸리는 시간의 최대 점수가 각 X 인덱스 안에 들어간다.
dt = [0] * (m + 1)
for question in questions:
# 뒤쪽에서 시작하여 온다
for j in range(m, question[1]-1, -1):
if dt[j] < dt[j-question[1]] + question[0]:
dt[j] = dt[j-question[1]] + question[0]
print(dt[-1])
댓글남기기