
[파이썬] 정규표현식 8 ( group () 괄호, group 이름 )
특정 패턴을 그룹으로 묶기 group ()
import re
r = re.compile('([0-9]{2,3})-([0-9]{3,4})-([0-9]{4})')
test1 = r.match('010-1111-3333')
print(test1, sep='\n')
print(test1.group())
print(test1.group(0))
print(test1.group(1))
print(test1.group(2))
print(test1.group(3))
<re.Match object; span=(0, 13), match='010-1111-3333'>
010-1111-3333
010-1111-3333
010
1111
3333
group 은 패턴 위치에 ()괄호로 정의를 한다.
패턴으로 ()괄호 또한 사용할 수 있지만 그럴 경우는 \를 넣은 \(를 해야 패턴으로 들어가는 것이다.
group이 하는 역할은 묶은 부분의 각 문자가 무엇인지를 알고 싶을 경우 사용한다.
- group() : 매칭된 문자열을 한꺼번에 반환
- group(0) : 매칭된 문자열을 한꺼번에 반환
- group(1) : 매칭된 문자열 중
그룹의 첫번째 것을 반환 - group(2) : 매칭된 문자열 중
그룹의 두번째 것을 반환 - group(3) : 매칭된 문자열 중
그룹의 세번째 것을 반환
특정 패턴을 그룹으로 묶기 : 그룹 이름 설정
그룹 개수가 많아지면 숫자로 그룹을 구분하기가 힘들어진다.
이때는 그룹에 이름을 지어주면 편리하다
형태 : (?P<그룹이름>패턴)
import re
r = re.compile('(?P<func>[a-zA-Z_]\w*)\(\"?\'?(?P<arg>\w+)\'?\"?\)')
test1 = r.match("print(1234)")
test2 = r.match("print('ab1234')")
print(test1, test2, sep='\n')
print(test1.group('func'))
print(test1.group('arg'))
print(test2.group('func'))
print(test2.group('arg'))
<re.Match object; span=(0, 11), match='print(1234)'>
<re.Match object; span=(0, 15), match="print('ab1234')">
print
1234
print
ab1234
위의 re.compile('(?P<func>[a-zA-Z_]\w*)\(\"?\'?(?P<arg>\w+)\'?\"?\)') 를 설명하자면
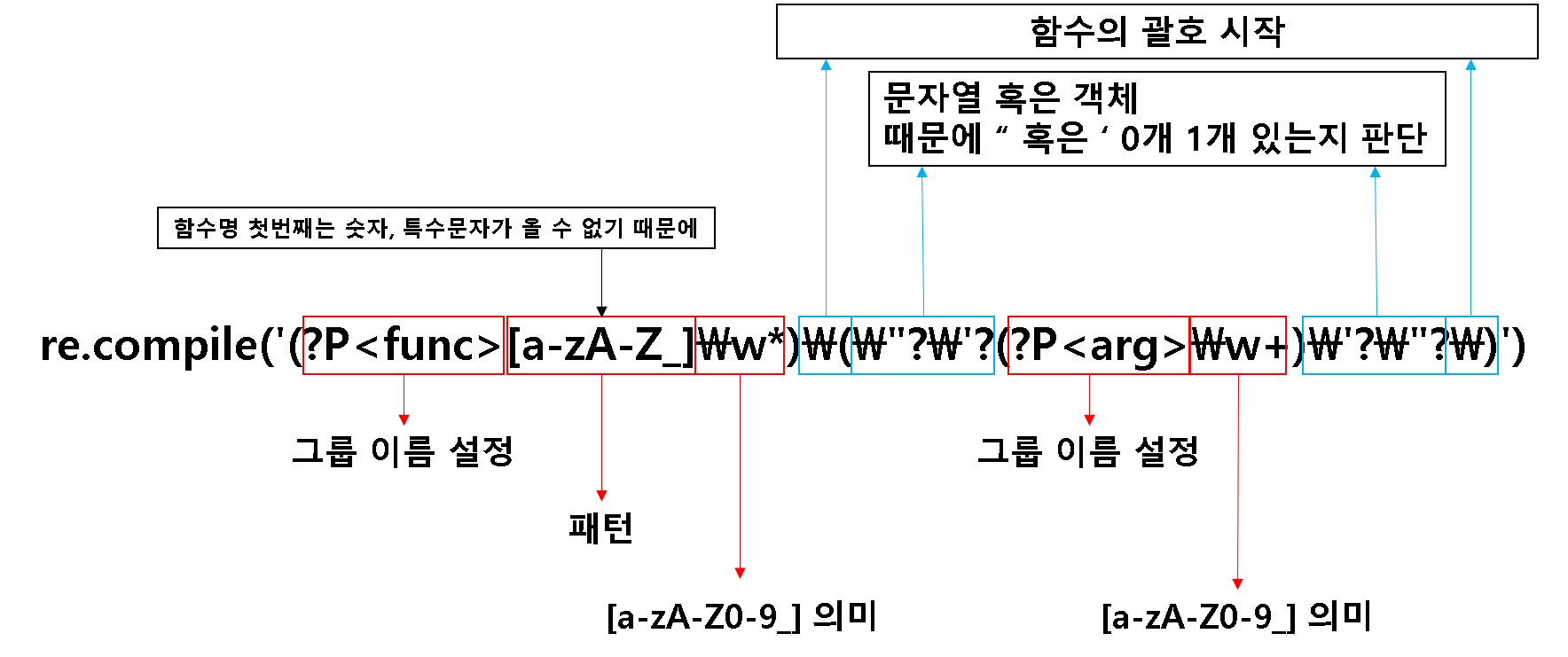
위의 이미지 처럼 뜻하는 바이다.
특정 패턴을 그룹으로 묶기 : 그룹에 * 와 + 사용
import re
r = re.compile('[a-z]+(.[a-z]+)*')
test1 = r.match("hello.world")
test2 = r.match("hello.world.what")
test3 = r.match("hello.a1234")
test4 = r.match("hello")
test5 = r.match("hello.1234")
print(test1, test2, test3, test4, test5, sep='\n')
print(test1.group(1))
print(test2.group(1))
print(test3.group(1))
print(test4.group(1))
print(test5.group(1))
<re.Match object; span=(0, 11), match='hello.world'>
<re.Match object; span=(0, 16), match='hello.world.what'>
<re.Match object; span=(0, 7), match='hello.a'>
<re.Match object; span=(0, 5), match='hello'>
<re.Match object; span=(0, 5), match='hello'>
.world
.what
.a
None
None
(.[a-z]+)* 의미는 해당 그룹 패턴이 0 번 혹은 1 번 이상 패턴을 잡는다는 의미이다. 즉, 있어도 되고 없어도 된다는 의미이다.
만약에 1번 이상 여러번 있으면 마지막에 있는 패턴을 그룹으로 이용한다.
특정 패턴을 그룹으로 묶기 : 그룹에 * 와 + 사용 시 $ 또한 사용
import re
r = re.compile('[a-z]+(.[a-z]+)*$')
test1 = r.match("hello.world")
test2 = r.match("hello.world.what")
test3 = r.match("hello.a1234")
test4 = r.match("hello")
test5 = r.match("hello.1234")
print(test1, test2, test3, test4, test5, sep='\n')
<re.Match object; span=(0, 11), match='hello.world'>
<re.Match object; span=(0, 16), match='hello.world.what'>
None
<re.Match object; span=(0, 5), match='hello'>
None
마지막 match 에 $ 의미
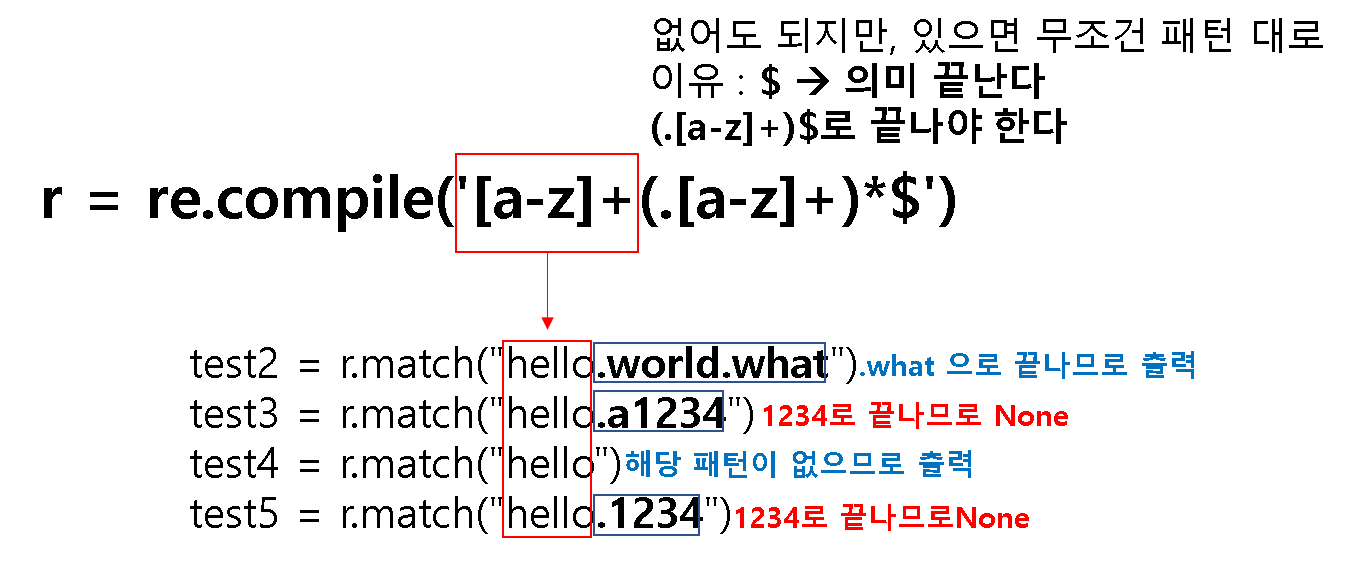
$ 가 붙어있는 패턴은 * 혹은 + 에 따라 문자열에 그 패턴이 있어도 되고 없어도 되지만, 문자열에 끝 부분에 글이 있다면 무조건 그 패턴으로 끝나야 한다.
- test3 번 같은 경우 끝날 때 .a1234 인데,
(.[a-z]+)*패턴에서 .a 만 맞고 1234는 틀리니 완벽하게 패턴(.[a-z]+)*와 맞지 않으니 None 이 뜬다. - test5 번 같은 경우 끝날 때 .1234 인데,
(.[a-z]+)*패턴에서 . 만 맞고 1234는 틀리니 완벽하게 패턴(.[a-z]+)*와 맞지 않으니 None 이 뜬다. - test4 번 같은 경우 끝날 때, 패턴
[a-z]+만 만족하고 뒤에 아에 없으므로(.[a-z]+)*의 패턴*없어도 되기 때문에 가능하다.
댓글남기기